Building Enterprise RAG Pipelines with AWS Technologies

DevDash Labs
.
Mar 17, 2025
Introduction
At DevDash, our research into enterprise AI integration has revealed Retrieval-Augmented Generation (RAG) as a critical architecture for organizations seeking to leverage generative AI with their proprietary data. In this analysis, we explore the combination of AWS Kendra and Bedrock as a powerful solution.
Understanding RAG Architecture
Retrieval-Augmented Generation addresses one of the fundamental challenges in enterprise AI adoption: connecting powerful language models with organization-specific knowledge bases. We identified three key components in effective RAG pipelines:
Ingestion Layer: Where enterprise data is processed, transformed, and indexed
Retrieval Engine: Which identifies and extracts relevant context based on queries
Generative Component: Where language models incorporate retrieved context to produce responses
This architecture significantly reduces the "hallucination problem" common in standard LLM implementations while enabling domain-specific knowledge integration without extensive model retraining.
AWS Implementation Strategy
Our DevDash engineering team has evaluated several cloud-based RAG architectures, finding AWS's combination of Kendra and Bedrock particularly effective for enterprise environments. Here's why:
Amazon Kendra Advantages
Semantic Search Capabilities: Kendra's ML-powered search extends beyond keyword matching, delivering contextually relevant results
Multi-format Support: Handles diverse document types from PDFs to Confluence pages
Enterprise Connectivity: Native integrations with common enterprise systems like SharePoint and Salesforce
RAG-optimized APIs: The Retrieve API specifically designed for generative AI augmentation
Amazon Bedrock Benefits
Model Flexibility: Access to multiple foundation models (Anthropic Claude, Amazon Titan) through a unified interface
Integration Simplicity: Bedrock Knowledge Bases provide streamlined data connections
Security Compliance: Data remains within your AWS environment, addressing common enterprise security concerns
Orchestration Tools: Bedrock Flow simplifies complex generative AI pipeline development
Implementation Architecture
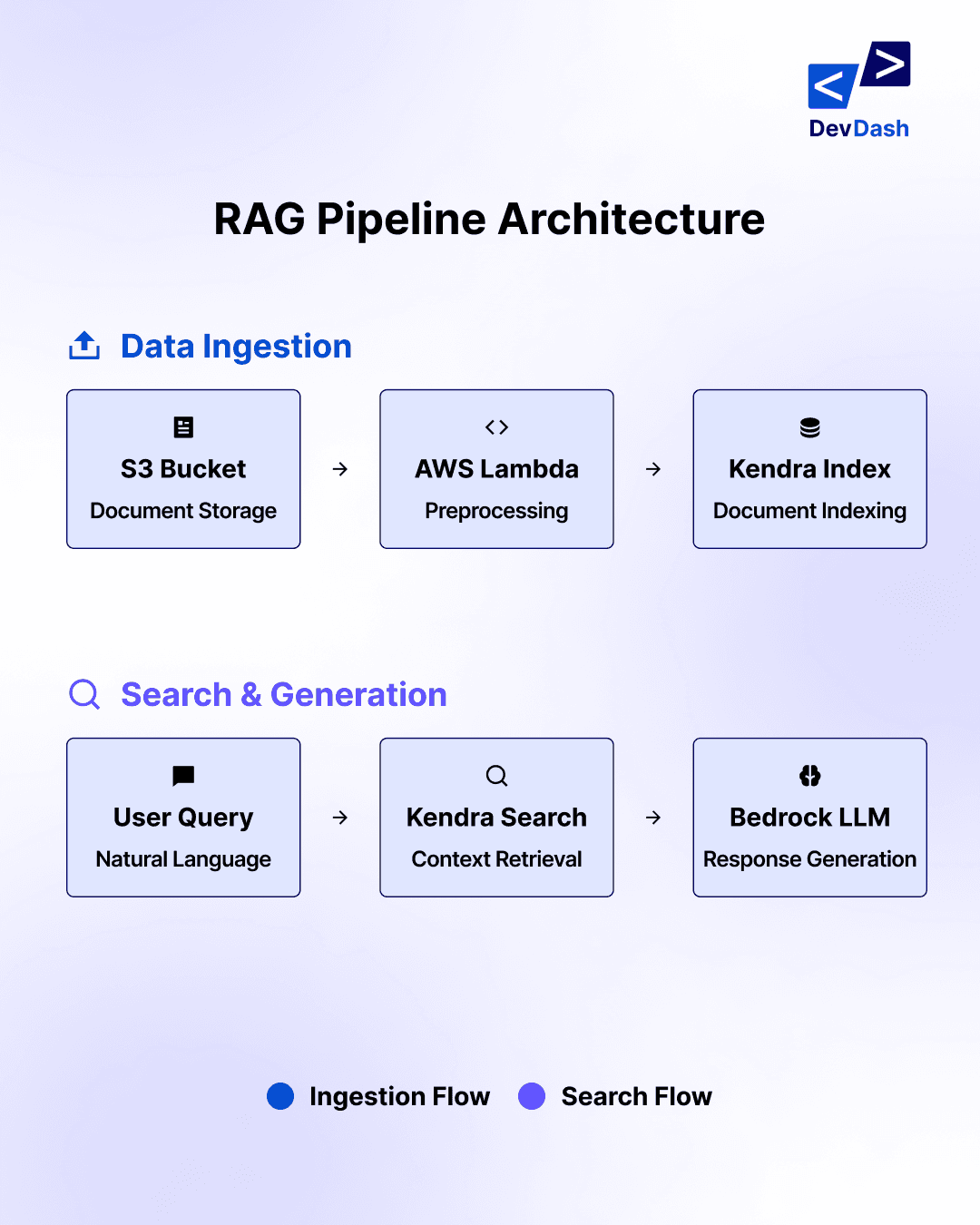
Fig i. RAG Pipeline Architecture
The four-stage implementation architecture involves:
Data Ingestion
# Example Lambda function for document preprocessing import boto3 def lambda_handler(event, context): textract = boto3.client('textract') comprehend = boto3.client('comprehend') # Extract text from document bucket = event['Records'][0]['s3']['bucket']['name'] key = event['Records'][0]['s3']['object']['key'] response = textract.detect_document_text( Document={'S3Object': {'Bucket': bucket, 'Name': key}} ) text = " ".join([item['Text'] for item in response['Blocks'] if item['BlockType'] == 'LINE']) # Enrich metadata entities = comprehend.detect_entities(Text=text, LanguageCode='en') return { 'text': text, 'metadata': entities['Entities'] }
This stage includes:
Document storage in S3
Text extraction using AWS Textract
Metadata enrichment with AWS Comprehend
Indexing via Kendra's BatchPutDocument API
2. Context Retrieval
When a query arrives, the system retrieves relevant context:
response = kendra.retrieve( IndexId='your-index-id', QueryText='What is the company's remote work policy?' ) for passage in response['Passages']: print(f"Passage: {passage['PassageText']}")
Our testing shows Kendra's semantic search capabilities significantly outperform traditional vector databases for complex enterprise queries.
3. Augmented Generation
The DevDash approach uses LangChain for orchestration between retrieval and generation:
from langchain.chains import RetrievalQA from langchain.llms import BedrockLLM from langchain.vectorstores import AmazonKendraRetriever # Set up retriever retriever = AmazonKendraRetriever(index_id="your-index-id") # Set up LLM from Bedrock llm = BedrockLLM(model="amazon-titan") # Create RAG pipeline qa_chain = RetrievalQA(llm=llm, retriever=retriever) # Query example query = "What is the company's remote work policy?" response = qa_chain.run(query)
4. Response Delivery
The final component formats responses for consumption:
{ "question": "What is the company's remote work policy?", "answer": "The company allows remote work up to three days per week.", "sources": [ { "title": "Remote Work Policy", "url": "https://s3.amazonaws.com/yourbucket/doc1.pdf" } ] }
DevDash Best Practices
Our implementation research has identified several critical success factors:
Optimize Document Chunking
Testing shows that chunking documents into 500-word segments optimizes retrieval precision. Larger chunks reduce contextual relevance while smaller chunks fragment conceptual integrity.
Implement Metadata Filtering
Organizations should develop a comprehensive metadata strategy during ingestion.
Secure Your Pipeline
Enterprise RAG implementations require comprehensive security measures:
IAM role-based access controls
KMS encryption for data at rest and in transit
VPC isolation for sensitive workloads
Monitor Performance Metrics
Tracking key performance indicators helps optimize RAG pipelines:
Query latency trends
Retrieval precision/recall metrics
Model performance comparisons
Conclusion
Our research demonstrates that AWS Kendra and Bedrock provide a robust foundation for enterprise RAG implementations. This architecture enables organizations to leverage their proprietary data with generative AI while maintaining security, scalability, and accuracy.
As generative AI continues to transform enterprise operations, properly implemented RAG pipelines will be essential for organizations seeking to extract maximum value from their data assets while minimizing the risks associated with pure LLM implementations.
Introduction
At DevDash, our research into enterprise AI integration has revealed Retrieval-Augmented Generation (RAG) as a critical architecture for organizations seeking to leverage generative AI with their proprietary data. In this analysis, we explore the combination of AWS Kendra and Bedrock as a powerful solution.
Understanding RAG Architecture
Retrieval-Augmented Generation addresses one of the fundamental challenges in enterprise AI adoption: connecting powerful language models with organization-specific knowledge bases. We identified three key components in effective RAG pipelines:
Ingestion Layer: Where enterprise data is processed, transformed, and indexed
Retrieval Engine: Which identifies and extracts relevant context based on queries
Generative Component: Where language models incorporate retrieved context to produce responses
This architecture significantly reduces the "hallucination problem" common in standard LLM implementations while enabling domain-specific knowledge integration without extensive model retraining.
AWS Implementation Strategy
Our DevDash engineering team has evaluated several cloud-based RAG architectures, finding AWS's combination of Kendra and Bedrock particularly effective for enterprise environments. Here's why:
Amazon Kendra Advantages
Semantic Search Capabilities: Kendra's ML-powered search extends beyond keyword matching, delivering contextually relevant results
Multi-format Support: Handles diverse document types from PDFs to Confluence pages
Enterprise Connectivity: Native integrations with common enterprise systems like SharePoint and Salesforce
RAG-optimized APIs: The Retrieve API specifically designed for generative AI augmentation
Amazon Bedrock Benefits
Model Flexibility: Access to multiple foundation models (Anthropic Claude, Amazon Titan) through a unified interface
Integration Simplicity: Bedrock Knowledge Bases provide streamlined data connections
Security Compliance: Data remains within your AWS environment, addressing common enterprise security concerns
Orchestration Tools: Bedrock Flow simplifies complex generative AI pipeline development
Implementation Architecture
Fig i. RAG Pipeline Architecture
The four-stage implementation architecture involves:
Data Ingestion
# Example Lambda function for document preprocessing import boto3 def lambda_handler(event, context): textract = boto3.client('textract') comprehend = boto3.client('comprehend') # Extract text from document bucket = event['Records'][0]['s3']['bucket']['name'] key = event['Records'][0]['s3']['object']['key'] response = textract.detect_document_text( Document={'S3Object': {'Bucket': bucket, 'Name': key}} ) text = " ".join([item['Text'] for item in response['Blocks'] if item['BlockType'] == 'LINE']) # Enrich metadata entities = comprehend.detect_entities(Text=text, LanguageCode='en') return { 'text': text, 'metadata': entities['Entities'] }
This stage includes:
Document storage in S3
Text extraction using AWS Textract
Metadata enrichment with AWS Comprehend
Indexing via Kendra's BatchPutDocument API
2. Context Retrieval
When a query arrives, the system retrieves relevant context:
response = kendra.retrieve( IndexId='your-index-id', QueryText='What is the company's remote work policy?' ) for passage in response['Passages']: print(f"Passage: {passage['PassageText']}")
Our testing shows Kendra's semantic search capabilities significantly outperform traditional vector databases for complex enterprise queries.
3. Augmented Generation
The DevDash approach uses LangChain for orchestration between retrieval and generation:
from langchain.chains import RetrievalQA from langchain.llms import BedrockLLM from langchain.vectorstores import AmazonKendraRetriever # Set up retriever retriever = AmazonKendraRetriever(index_id="your-index-id") # Set up LLM from Bedrock llm = BedrockLLM(model="amazon-titan") # Create RAG pipeline qa_chain = RetrievalQA(llm=llm, retriever=retriever) # Query example query = "What is the company's remote work policy?" response = qa_chain.run(query)
4. Response Delivery
The final component formats responses for consumption:
{ "question": "What is the company's remote work policy?", "answer": "The company allows remote work up to three days per week.", "sources": [ { "title": "Remote Work Policy", "url": "https://s3.amazonaws.com/yourbucket/doc1.pdf" } ] }
DevDash Best Practices
Our implementation research has identified several critical success factors:
Optimize Document Chunking
Testing shows that chunking documents into 500-word segments optimizes retrieval precision. Larger chunks reduce contextual relevance while smaller chunks fragment conceptual integrity.
Implement Metadata Filtering
Organizations should develop a comprehensive metadata strategy during ingestion.
Secure Your Pipeline
Enterprise RAG implementations require comprehensive security measures:
IAM role-based access controls
KMS encryption for data at rest and in transit
VPC isolation for sensitive workloads
Monitor Performance Metrics
Tracking key performance indicators helps optimize RAG pipelines:
Query latency trends
Retrieval precision/recall metrics
Model performance comparisons
Conclusion
Our research demonstrates that AWS Kendra and Bedrock provide a robust foundation for enterprise RAG implementations. This architecture enables organizations to leverage their proprietary data with generative AI while maintaining security, scalability, and accuracy.
As generative AI continues to transform enterprise operations, properly implemented RAG pipelines will be essential for organizations seeking to extract maximum value from their data assets while minimizing the risks associated with pure LLM implementations.
Introduction
At DevDash, our research into enterprise AI integration has revealed Retrieval-Augmented Generation (RAG) as a critical architecture for organizations seeking to leverage generative AI with their proprietary data. In this analysis, we explore the combination of AWS Kendra and Bedrock as a powerful solution.
Understanding RAG Architecture
Retrieval-Augmented Generation addresses one of the fundamental challenges in enterprise AI adoption: connecting powerful language models with organization-specific knowledge bases. We identified three key components in effective RAG pipelines:
Ingestion Layer: Where enterprise data is processed, transformed, and indexed
Retrieval Engine: Which identifies and extracts relevant context based on queries
Generative Component: Where language models incorporate retrieved context to produce responses
This architecture significantly reduces the "hallucination problem" common in standard LLM implementations while enabling domain-specific knowledge integration without extensive model retraining.
AWS Implementation Strategy
Our DevDash engineering team has evaluated several cloud-based RAG architectures, finding AWS's combination of Kendra and Bedrock particularly effective for enterprise environments. Here's why:
Amazon Kendra Advantages
Semantic Search Capabilities: Kendra's ML-powered search extends beyond keyword matching, delivering contextually relevant results
Multi-format Support: Handles diverse document types from PDFs to Confluence pages
Enterprise Connectivity: Native integrations with common enterprise systems like SharePoint and Salesforce
RAG-optimized APIs: The Retrieve API specifically designed for generative AI augmentation
Amazon Bedrock Benefits
Model Flexibility: Access to multiple foundation models (Anthropic Claude, Amazon Titan) through a unified interface
Integration Simplicity: Bedrock Knowledge Bases provide streamlined data connections
Security Compliance: Data remains within your AWS environment, addressing common enterprise security concerns
Orchestration Tools: Bedrock Flow simplifies complex generative AI pipeline development
Implementation Architecture
Fig i. RAG Pipeline Architecture
The four-stage implementation architecture involves:
Data Ingestion
# Example Lambda function for document preprocessing import boto3 def lambda_handler(event, context): textract = boto3.client('textract') comprehend = boto3.client('comprehend') # Extract text from document bucket = event['Records'][0]['s3']['bucket']['name'] key = event['Records'][0]['s3']['object']['key'] response = textract.detect_document_text( Document={'S3Object': {'Bucket': bucket, 'Name': key}} ) text = " ".join([item['Text'] for item in response['Blocks'] if item['BlockType'] == 'LINE']) # Enrich metadata entities = comprehend.detect_entities(Text=text, LanguageCode='en') return { 'text': text, 'metadata': entities['Entities'] }
This stage includes:
Document storage in S3
Text extraction using AWS Textract
Metadata enrichment with AWS Comprehend
Indexing via Kendra's BatchPutDocument API
2. Context Retrieval
When a query arrives, the system retrieves relevant context:
response = kendra.retrieve( IndexId='your-index-id', QueryText='What is the company's remote work policy?' ) for passage in response['Passages']: print(f"Passage: {passage['PassageText']}")
Our testing shows Kendra's semantic search capabilities significantly outperform traditional vector databases for complex enterprise queries.
3. Augmented Generation
The DevDash approach uses LangChain for orchestration between retrieval and generation:
from langchain.chains import RetrievalQA from langchain.llms import BedrockLLM from langchain.vectorstores import AmazonKendraRetriever # Set up retriever retriever = AmazonKendraRetriever(index_id="your-index-id") # Set up LLM from Bedrock llm = BedrockLLM(model="amazon-titan") # Create RAG pipeline qa_chain = RetrievalQA(llm=llm, retriever=retriever) # Query example query = "What is the company's remote work policy?" response = qa_chain.run(query)
4. Response Delivery
The final component formats responses for consumption:
{ "question": "What is the company's remote work policy?", "answer": "The company allows remote work up to three days per week.", "sources": [ { "title": "Remote Work Policy", "url": "https://s3.amazonaws.com/yourbucket/doc1.pdf" } ] }
DevDash Best Practices
Our implementation research has identified several critical success factors:
Optimize Document Chunking
Testing shows that chunking documents into 500-word segments optimizes retrieval precision. Larger chunks reduce contextual relevance while smaller chunks fragment conceptual integrity.
Implement Metadata Filtering
Organizations should develop a comprehensive metadata strategy during ingestion.
Secure Your Pipeline
Enterprise RAG implementations require comprehensive security measures:
IAM role-based access controls
KMS encryption for data at rest and in transit
VPC isolation for sensitive workloads
Monitor Performance Metrics
Tracking key performance indicators helps optimize RAG pipelines:
Query latency trends
Retrieval precision/recall metrics
Model performance comparisons
Conclusion
Our research demonstrates that AWS Kendra and Bedrock provide a robust foundation for enterprise RAG implementations. This architecture enables organizations to leverage their proprietary data with generative AI while maintaining security, scalability, and accuracy.
As generative AI continues to transform enterprise operations, properly implemented RAG pipelines will be essential for organizations seeking to extract maximum value from their data assets while minimizing the risks associated with pure LLM implementations.



